Improving query execution latencies

This article was originally published on the DFINITY Medium blog here by Andriy Berestovskyy.
Background
The Internet Computer can host a full dapp — frontend, backend, and data. Users can deploy their dapp as a canister (smart contract).
Just like HTTP POST and GET methods, the Internet Computer Protocol supports two types of messages: updates and queries. An update message is executed on all subnet nodes and persists canister state changes. A query message discards state changes and typically runs on a single node.
Web caching is a well-known technique to accelerate requests and reduces peak server load. However, the common caching challenge is data consistency, and the decentralized Web3 world raises the bar even higher.
Keep on reading to find out how the Internet Computer implements in-replica query caching.
Query cache properties
The Internet Computer implements an in-replica query cache with the following features:
- Transparency: the cache is completely transparent, there is no need to worry about cache validity, max age etc.
- LRU cache replacement policy: the query cache discards least recently used (LRU) entries first. On a cache hit into a valid entry, that entry becomes the most recently used. Entries that remain unused for some time become less recently used and are eventually evicted from the cache.
- Cache validity: the implementation ensures that, for a given replicated state, any valid cache entry contains the most up-to-date result of query execution.
Cache validity is the main challenge of the query cache implementation, so let’s delve further!
Cache invalidation factors
Cache validity means that a cached result matches the result of actual query execution.
The query cache is a key-value map, where each key is a tuple of (source, receiver, method, payload) and value is a result of the query execution. A cache hit happens when all 4 key components match.
But even if there is a hit, is the cached result still up-to-date? The result might become stale after:
- State changes: update calls or canister upgrades alter the state, so the cached result is no longer up-to-date.
- Cycle balance and system time: the canister is periodically charged for the CPU and memory resources, execution, ingress messages, etc. The query might take a different execution path based on a specific balance level or at a particular point in time. Therefore, if the canister balance or system time changes, the cache entry becomes stale.
#[query]
fn event_started() -> Option<String> {
if ic_cdk::api::time() > EVENT_START_TIME {
Some("The new event has started!")
} else {
None
}
}
Given that many changing factors and the live data freshness property, the data might become stale too quickly to achieve high query cache efficiency. In fact, the initial implementation of the query cache released in May 2023 was just that.
The cache hit ratio of the initial version was about 10%. Most of the time, the cache was invalidated due to cycle balance and system time changes. Is there room for improvement?
Improving cache invalidations
One way to improve cache invalidations is to determine whether the query execution depends on the cycle balance and system time:
- Query execution does not modify the blockchain state: this Internet Computer property enables executing queries in any order and cache the result of their execution.
- Query execution is deterministic: the result of the execution is always the same, provided the same state, cycles balance, and system time. This property is also crucial for query caching.
- Tracking query execution: the system can monitor if the query attempted to read the current cycle balance or system time.
- Ignoring cache invalidations: since most queries never read the balance and time, their cached result remains valid even when the balance or time changes.
Results
With the query execution tracking, the cache hit ratio has increased from around 10% to 50%:
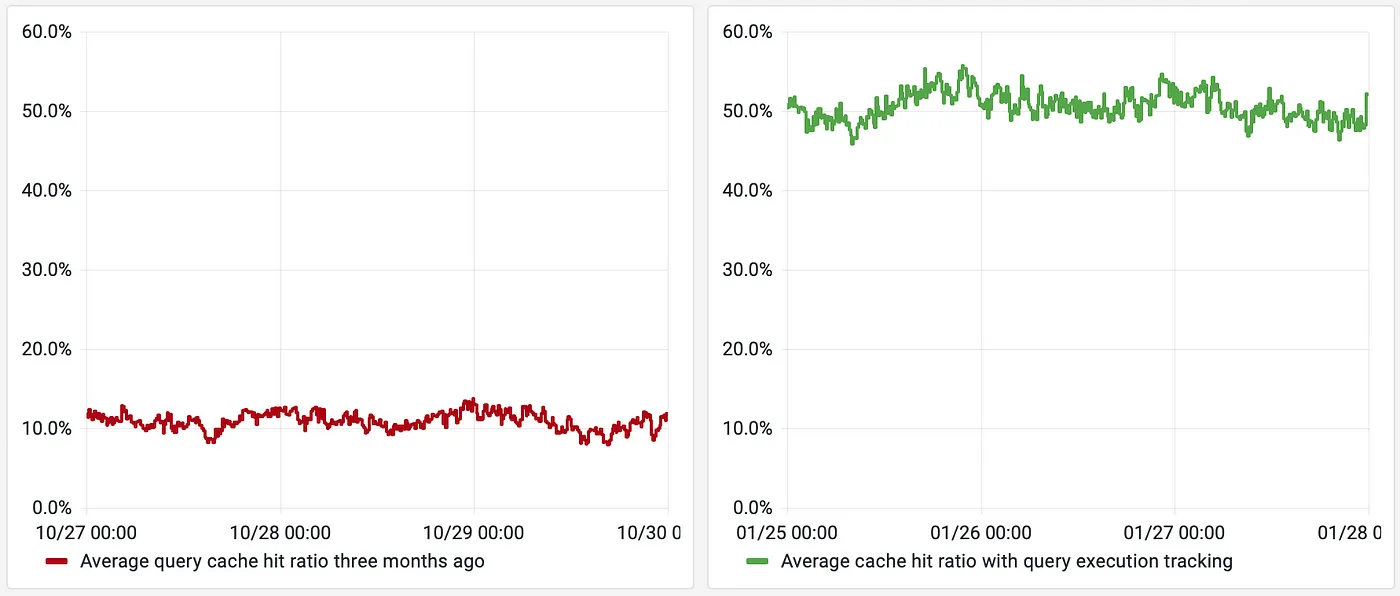
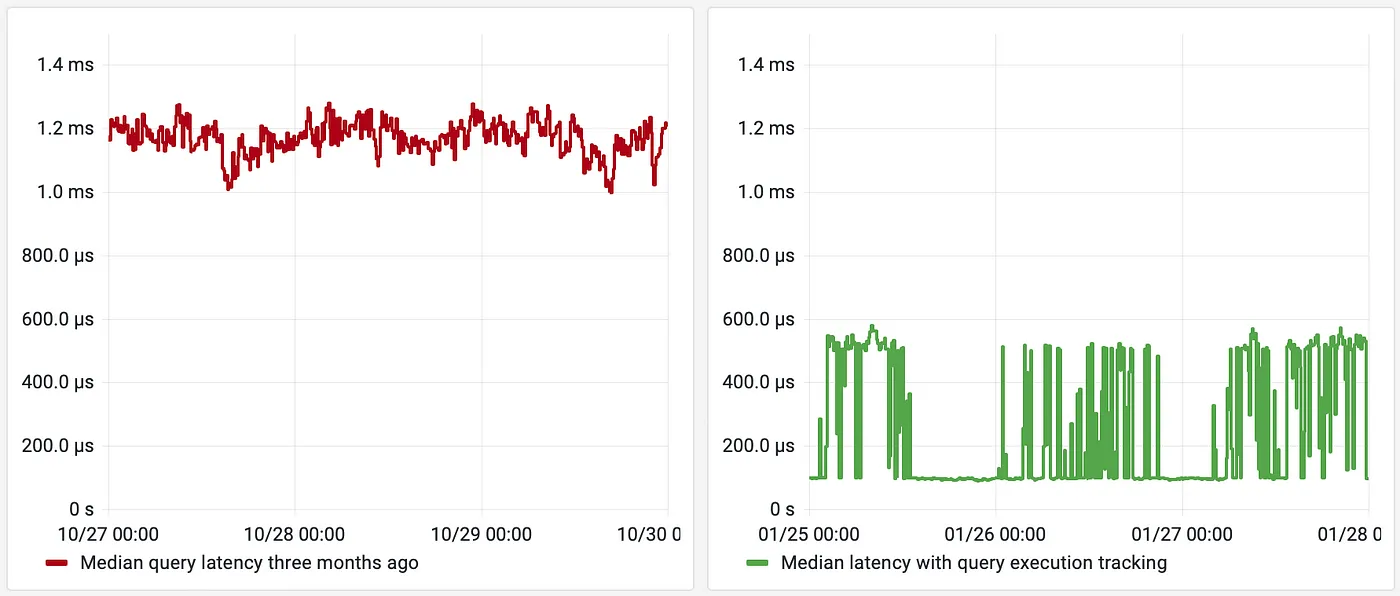
Also, the median query latency is also improved from around 1.2ms down to 0.4ms. When the cache hit ratio reaches above 50%, the median goes down to just 0.1ms:
Takeaways: How to improve query latencies?
Developers can improve cache efficiency of their queries even more by following these tips.
- Avoid unnecessary calls to the time() and balance() System APIs:
#[query]
fn status() -> (String, u64) {
(
STATUS.clone(),
ic_cdk::api::time() // ← this is BAD for caching!
)
}
- Try to move the System API calls to places where they are actually used:
#[query]
fn ready_time() -> Option<u64> {
let now = ic_cdk::api::time(); // ← this is BAD for caching!
if STATUS.is_ready() {
// The `time()` should be called here, when the STATUS is ready.
Some(now)
} else {
None
}
}
The new functionality is transparent and available on all the subnets and local development environments.